Introducing MuZero
A PyTorch implementation of DeepMind's MuZero agent to do planning with a learned model
By Michael Hu
2 min read
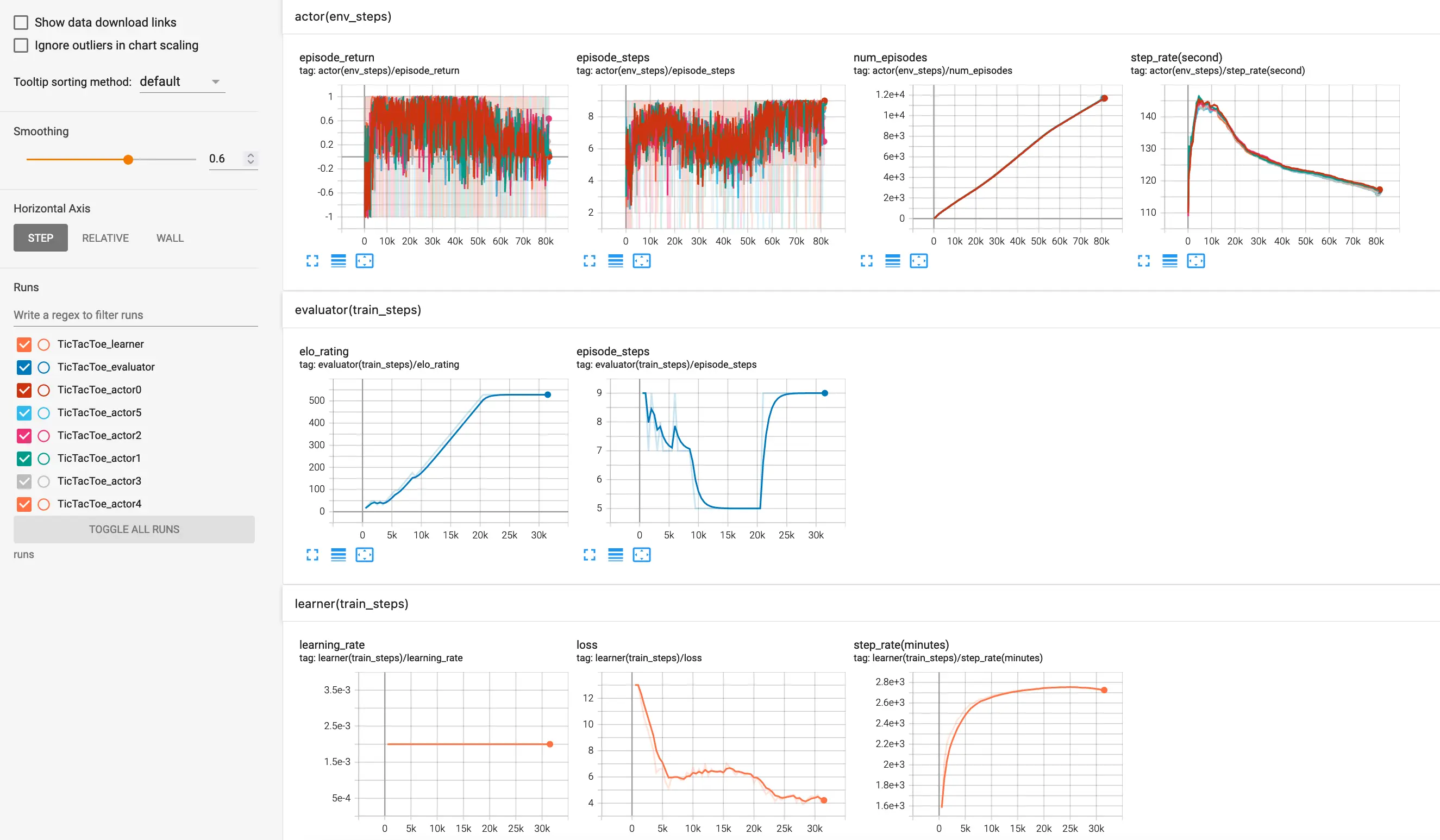
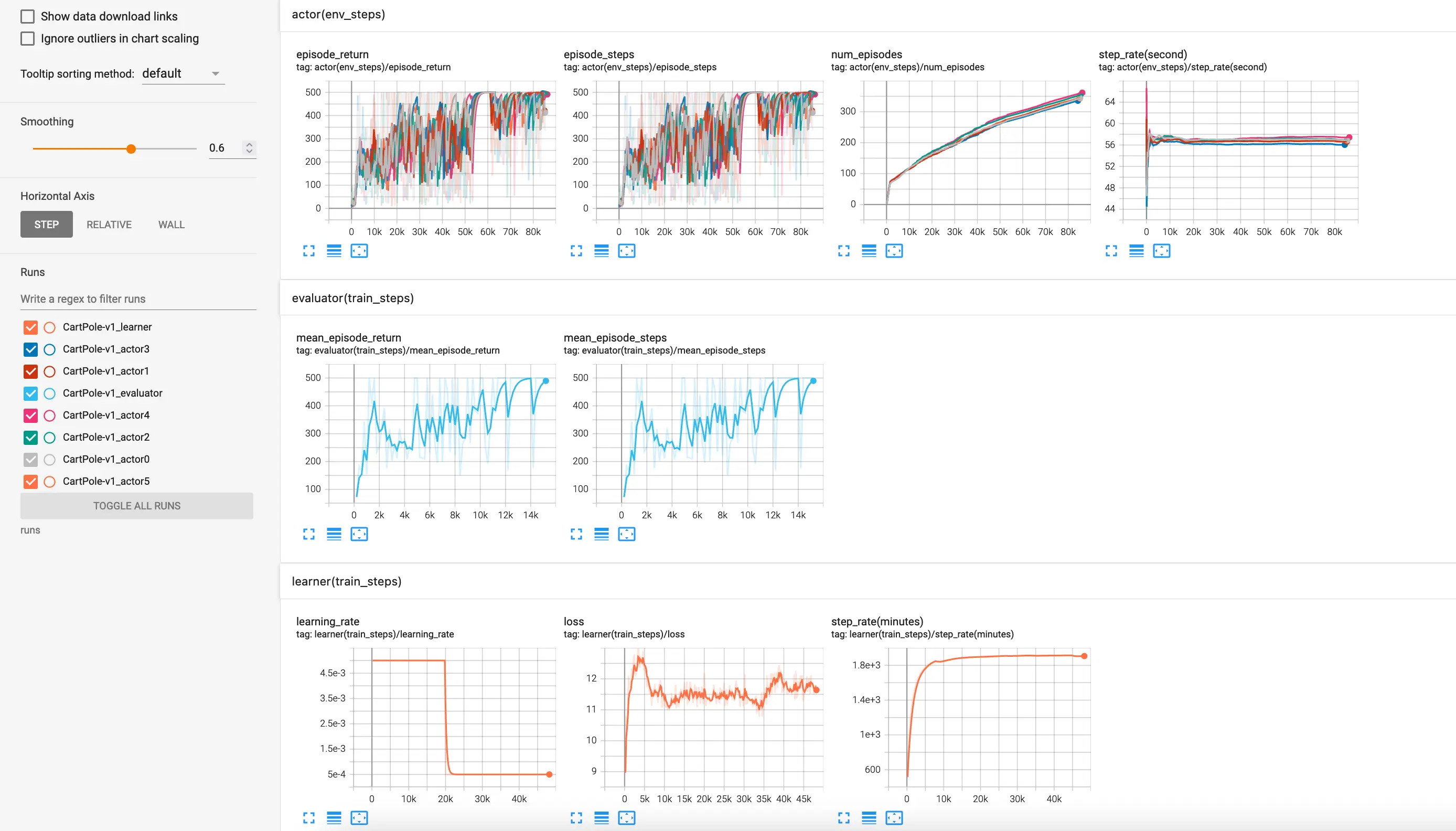
We are excited to introduce our most recent project MuZero, an open-source implementation of DeepMind's MuZero algorithm [1], an advancement over the famous AlphaZero algorithm [2]. In contrast to the AlphaZero agent, which is limited to turn-based, two-player, zero-sum games, the MuZero agent can also play single-player games, such as Atari games. In addition, the MuZero agent uses a learned model, thereby relaxing the requirements and making it suitable for addressing more real-world problems.
The project was implemented in PyTorch and provides comprehensive support for training, monitoring. For those interested, the source code for the project can be found in this repository.