Introducing AlphaZero
A PyTorch implementation of DeepMind's AlphaZero agent to play two-player, zero-sum strategy board games like Go and Gomoku.
By Michael Hu
2 min read
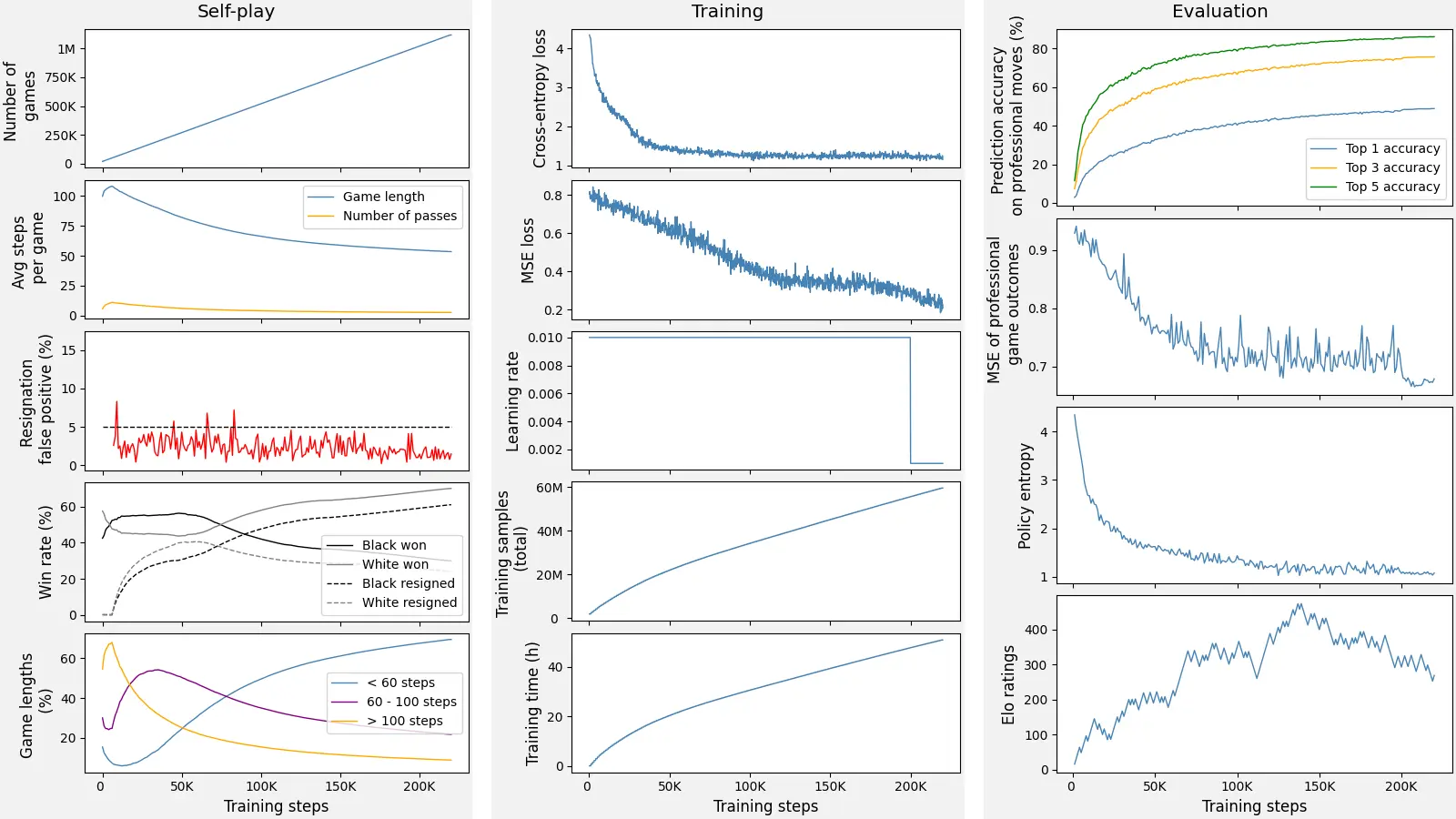
We are excited to introduce our most recent project AlphaZero, an open-source implementation of DeepMind's groundbreaking AlphaZero algorithm [1]. AlphaZero is an advancement over the initial AlphaGo algorithm [2], which defeated the world best players in Go.
The project was implemented in PyTorch and provides comprehensive support for training, monitoring, and analyzing the AlphaZero agent specifically tailored for Go and Free-style Gomoku board games. We hope it can mark a noteworthy achievement in this field.
[UPDATE 2023-12-23]: The project is now part of my new book The Art of Reinforcement Learning: Fundamentals, Mathematics, and Implementation with Python